実践 4(前半)
概要
ついに最後の実践です。
この実践では無償で提供されている外部モジュールを使って、ウェブサイトにある情報をエクセルに書き込むという作業を自動化してくれるプログラムを書きます。具体的には、外務省のサイトに掲載されているSDGsに取り組んでいる企業の企業名とそのリンクをエクセルのセルにそれぞれ書き込んでくれるプログラムを書きます。
今回もなかなか難易度が高いので手順を一つ一つ解説していきながらの実践になります。
さて、今までサイト上で使ってきたIDEであるTrinketでは外部モジュールを使用できないので、ここからの作業は各自のパソコン上で行うことになります。パソコンにPythonがインストールされてない人はインストールしましょう。インストールの手順はこちらで説明しています。
ではまず、どのようなモジュールを使えば目標が達成できるかを考えます。
あるサイトの内容を抽出し、エクセルへの書き込むところまで一貫して行ってくれるモジュールがあれば便利なのですが、おそらくそのようなものは存在しません。が、サイトの内容を抽出するモジュールと、データをエクセルに書き込んでくれるモジュールはありそうな気がしますがわかりません。 そんなときはどうするかというと、Googleで調べます。Googleで「Python サイト 保存」などで検索すると、なにやら「Requests」や「BeautifulSoup」というモジュール名がでてきますね。また、「Python エクセル」で調べると「openpyxl」というモジュールが出てきます。それぞれのモジュールを自作のコードで組み合わせることで目的が達成されそうです。
というわけでこの実践では「Requests」、「BeautifulSoup」、「openpyxl」という3つの外部モジュールを使います。すこしだけこれらのモジュールの紹介をしたいと思います。
note
Requests
Requestsは、ネット上にある情報をPythonで読み込むためのモジュールです。私達は普段はGoogle ChromeやInternet Explorerといったブラウザでインターネット上にある情報にアクセスをしていますが、Requestsを使うことでPythonを通じてインターネット上にある情報にアクセスができるようになります。
BeautifulSoup
BeautifulSoupは、Requestsなどで得られた情報を分析するツールです。私達が普段目にするサイトはHTMLという言語で表示内容や表示方法が指示されており、これに従って各ブラウザはパソコンの画面上にサイトの内容を表示します。BeautifulSoupを使うことで、Requestsを通じて得られたHTMLがどのような内容であるかの分析ができます。
openpyxl
openpyxlは、Pythonを使ってエクセルファイルを操作するためのモジュールです。
モジュールのインストール
それではこれらのモジュールをインストールしましょう。
外部モジュールのインストール方法はPythonのバージョンによって異なりますが、Pythonのバージョンが3.4以上であればpipインストールという方法が主に用いられます。
pipインストールは、Windowsのコマンドプロンプトとよばれる画面を通じて行います。コマンドプロンプトとは、文字を使ってWindowsに指示を送る画面です。
コマンドプロンプトの画面を開く方法はいくつかあります。Windowsキー+Rあるいは、Ctrl+Shift+Escでタスクマネージャーを開いて左上の ファイル > 新しいタスクの実行 をクリックすることで「ファイル名を指定して実行」の画面を表示させ、ファイル名にcmdと入力することでコマンドプロンプトを開くことができます。
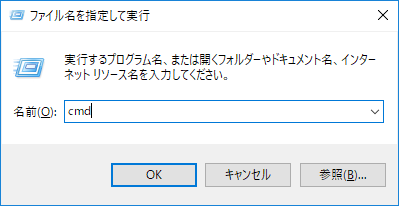
また画面左下のWindowsアイコンを右クリックしてコマンドプロンプト(C)をクリックすることでも開くことができます。
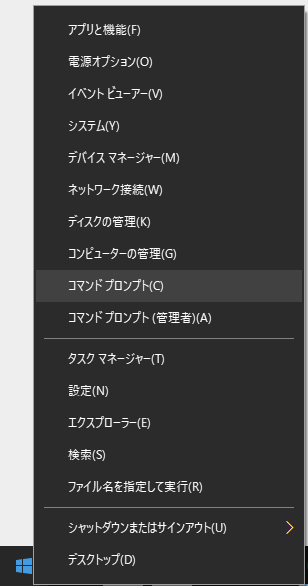
コマンドプロンプトを開くと、下のような黒い背景に白文字の画面が表示されます。
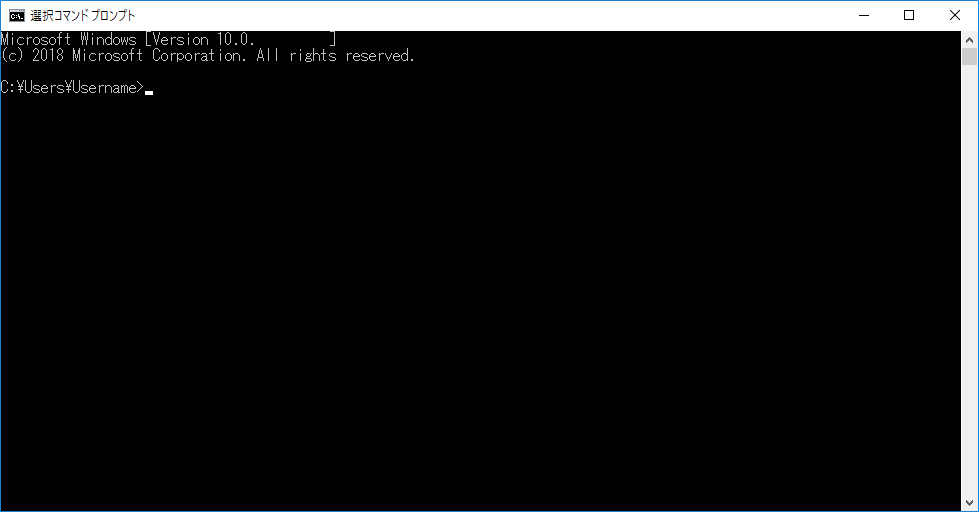
上の画像「Username」にはみなさんの場合はログインしている自分のユーザー名が書かれているはずです。
Pythonをパソコンにインストールする際に「Pathに追加」を選択していればこの画面上にpip install ○○(モジュールのpipインストールの際の名前)と入力するだけで外部モジュールをインストールすることができます。モジュールの名前とpipインストールの際の名前が異なる場合があります。pipインストールの際の名前は各モジュールのホームページや、PythonのパッケージをまとめているPyPIに記載されているので、確認してからインストールしましょう。
それではまずRequestsをインストールしましょう。Requestsのpipインストールの際の名前はRが小文字になった「requests」です。下の画像のようにコマンドプロンプトの画面に pip install requestsと入力しましょう。
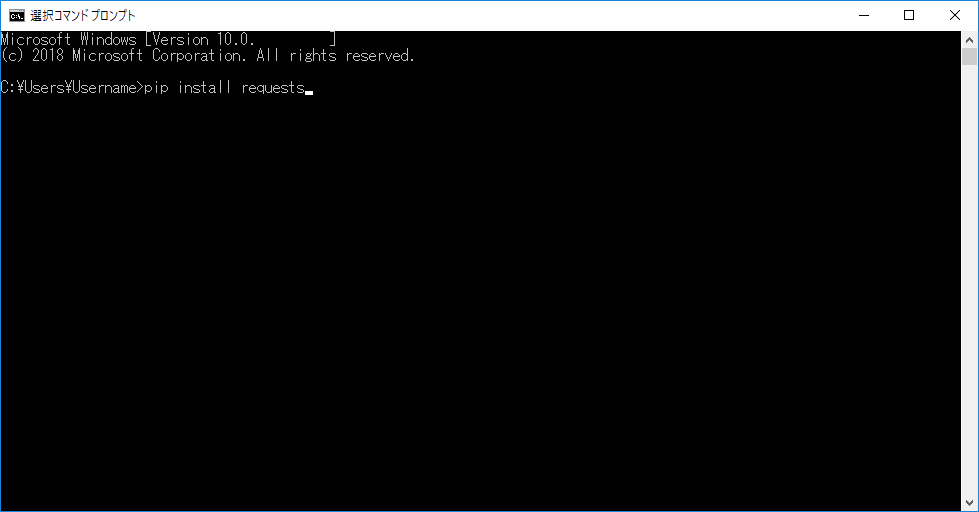
この状態でEnterキーを押せばRequestsのインストールが開始されます。
上の画像のはインストールが完了した状態です。
ついでにBeautifulSoupとopenpyxlもインストールしておきましょう。BeautifulSoupのpipインストールの際の名前は「beautifulsoup4」で、openpyxlのpipインストールの際の名前は変わらず「openpyxl」です。先程の画面にpip install beautifulsoup4 openpyxlというようにpip installという文字のあとに2つのモジュール名にスペースでを入れて入力してEnterキーを押すと、2つを一度にインストールすることができます。
モジュールの使い方 ~Requests、BeautifulSoup編~
外部モジュールを使うためには、まずそのモジュールの使い方を知る必要があります。モジュールの使い方に関する文書は開発者によって用意されていますが、大抵の場合英語です。幸いRequestsとBeautifulSoupに関する文書は有志による日本語訳が存在します。
Requestsの使い方: http://jp.python-Requests.org/en/latest/
BeautifulSoupの使い方: http://kondou.com/BS4/
大抵の場合各モジュールの基本的な使い方に関しては具体的なコードと共にに紹介されています。いままで使ったことのないモジュールを使いたい場合は、文書で用意された手順に従って実際にモジュールを使ってみることが大事です。
本来は各モジュールの基本的な使い方を紹介するべきなのですが、長くなってしまうのでここではこの実践で使う機能のみを解説します。
まずはRequestsとBeautifulSoupの機能をIDLEの対話モードのインタープリタを使ってみていきます。
それではIDLEの対話モードのインタープリタに以下のコードを書いてみてください。
>>> import requests
>>> from bs4 import BeautifulSoup
>>> url = 'https://www.mofa.go.jp/mofaj/gaiko/oda/sdgs/case/goal1.html'
>>> result = requests.get(url)
>>> pagecontent = result.content
>>> soup = BeautifulSoup(pagecontent, 'html.parser')
画面からはわかりませんがこの6行でかなりの処理が行われています。
1行目ではrequestsのモジュールをインポートしています。
2行目では、BeautifulSoupをインポートしています。from bs4 import BeautifulSoupとなっているのは、BeautifulSoupというモジュールはbs4というパッケージの中に存在しているからです。
3行目では、「url」という変数にurlとなる文字列として登録しています。urlに指定しているのは総務省JAPAN SDGs Action Platformの「取組事例 1: 貧困をなくそう」です。
4行目では、Requestsのget()メソッドを使ってurl先の情報を入手しています。get()メソッドの引数にはurlの文字列を入れます。このメソッドを実行すると、url先の情報はresult.contentでアクセスが可能となります。
5行目では、4行目で得たurl先の情報であるresult.contentのうち、HTMLに該当する部分を「pagecontent」という変数に入れています。
6行目ではbs4のBeautifulSoup()メソッドを使って「pagecontent」のHTMLを要素ごとにパース(解析)しています。BeautifulSoup()メソッドの1つ目の引数にHTMLを、2つ目の引数にはそのHTMLを解析するためのパーサー(構文解析器)の種類を入れます。パーサーの種類については今回の実践においては気にする必要はありません。今回はPythonに標準搭載されているhtml.parserを使います。
続いてインタープリタに
>>> print(soup.prettify())
と入力してエンターを押すと、BeautifulSoupによって各要素ごとにきれいに分解され、見やすくされたHTMLの内容を見ることができます。
下はprint(soup.prettify())で得られたHTMLの一部を抜き取ったものです。
</head>
<body id="case">
<div id="container">
<div id="head">
<div class="inner">
<div class="tool">
<div class="tool-link">
<ul class="link_border">
<li class="pc_only">
<a href="#main">
本文へ
</a>
</li>
<li lang="en">
<a href="https://www.mofa.go.jp/policy/oda/page22e_000793.html">
English
</a>
</li>
--------------------(中略)--------------------
<div id="main">
<div class="inner">
<div id="main_contents">
<div class="section" id="case_main">
<div id="goal_1">
<h1 class="case_h">
<span>
取組事例
</span>
<span>
1: 貧困をなくそう
</span>
</h1>
<ul class="c_links">
<li>
<a href="#c1">
あ行
</a>
</li>
--------------------(中略)--------------------
<div class="kana_line" id="c1">
<h2>
あ行
</h2>
<ul>
<li>
<a class="exlink" href="https://www.itoki.jp/topics/solution/nona-carbon-offset.html" target="_blank">
株式会社イトーキ
</a>
</li>
</ul>
</div>
<div class="kana_line" id="c2">
<h2>
か行
</h2>
<ul>
<li>
<a class="exlink" href="http://www.city.kisarazu.lg.jp/12,66100,24,157.html" target="_blank">
千葉県木更津市消費生活センター
</a>
</li>
<li>
<a class="exlink" href="https://www.jircas.go.jp/ja/about/sdgs" target="_blank">
国立研究開発法人国際農林水産業研究センター(国際農研)
</a>
</li>
</ul>
</div></pre>
(注: 上記のHTMLは2018/8/10時点での外務省作成のJAPAN SDGs Action Platformの「取組事例 1: 貧困をなくそう」のソースコードを一部抜き取ったものです。)
ここで、HTMLについて少し説明をしておきます。
HTMLはタグと呼ばれるもので区切られています。<>が区分の始まりを表し、</>がその区分の終わりを表します。<>の中身は、最初にタグの名前(区分の名前)、次にそのタグの属性(文字の色などの情報)が書かれています。上のHTMLを見ると、取組事例はすべて<div id="goal_1">の区分に記載されていることがわかります。<div id="goal_1">は、id属性が"goal_1"であるdivというタグであることを指します。この<div id="goal_1">の区分の中を見ると、各取組事例とurlは<a>というタグ名の区分に含まれていることもわかります。
これらのタグを頼りに今度はBeautifulSoupを使ってでリンクの部分だけを抽出していきます。さきほどの対話モードのインタープリタの続きに次のコードを入力しましょう。
>>> soup_div = soup.find('div', {'id': 'goal_1'})
>>> list_of_links = soup_div.find_all('a')
>>> list_of_links[10].text
'千葉県木更津市消費生活センター'
>>> list_of_links[10].get('href')
'http://www.city.kisarazu.lg.jp/12,66100,24,157.html'
1行目では、BeautifulSoupのfind()メソッドでHTMLから、最初に現れる「id="goal_1"」である<div>タグを探し出し、その中身を抽出し、「soup_div」という変数に入れています。
2行目では、BeautifulSoupのfind_all()メソッドで先程抽出した「soup_div」の中身からさらに<a>タグの部分のみをすべて抽出し、「list_of_links」という変数に入れています。find_all()メソッドで抽出された内容はリスト型データとして記憶されます。
3行目では「list_of_links」の11番目の要素のテキストの部分、すなわち取組事例を行っている団体名の部分を取得することを指示しています。
4行目では3行目の結果が返されています。2018/8/10現在、「list_of_links」の11番目の要素は「千葉県木更津市消費生活センター」のようです。
5行目では、BeautifulSoupのget()メソッドで「list_of_links[10]」内のhref属性の中身、つまりurlを抽出することを指示しています。
6行目では5行目の結果が返されています。
以上がRequestsとBeautifulSoupの、最終的に書くプログラムで使う機能の紹介でした。
BeautifulSoupを使うにあたっては、HTMLがどのように書かれているかの知識もある程度必要だったので、HTMLに馴染みのない人はちょっと大変だったかもしれません。
後半ではopenpyxlの機能についてみていき、RequestsとBeautifulSoupと組み合わせて実際にプログラムを書いていきます。